3.2 分布式处理框架 MapReduce
3.2.1 什么是MapReduce
- 源于Google的MapReduce论文(2004年12月)
- Hadoop的MapReduce是Google论文的开源实现
- MapReduce优点: 海量数据离线处理&易开发
- MapReduce缺点: 实时流式计算
3.2.2 MapReduce编程模型
- MapReduce分而治之的思想
- 数钱实例:一堆钞票,各种面值分别是多少
- 单点策略
- 一个人数所有的钞票,数出各种面值有多少张
- 分治策略
- 每个人分得一堆钞票,数出各种面值有多少张
- 汇总,每个人负责统计一种面值
- 解决数据可以切割进行计算的应用
- 单点策略
- 数钱实例:一堆钞票,各种面值分别是多少
- MapReduce编程分Map和Reduce阶段
- 将作业拆分成Map阶段和Reduce阶段
- Map阶段 Map Tasks 分:把复杂的问题分解为若干"简单的任务"
- Reduce阶段: Reduce Tasks 合:reduce
MapReduce编程执行步骤
- 准备MapReduce的输入数据
- 准备Mapper数据
- Shuffle
- Reduce处理
- 结果输出
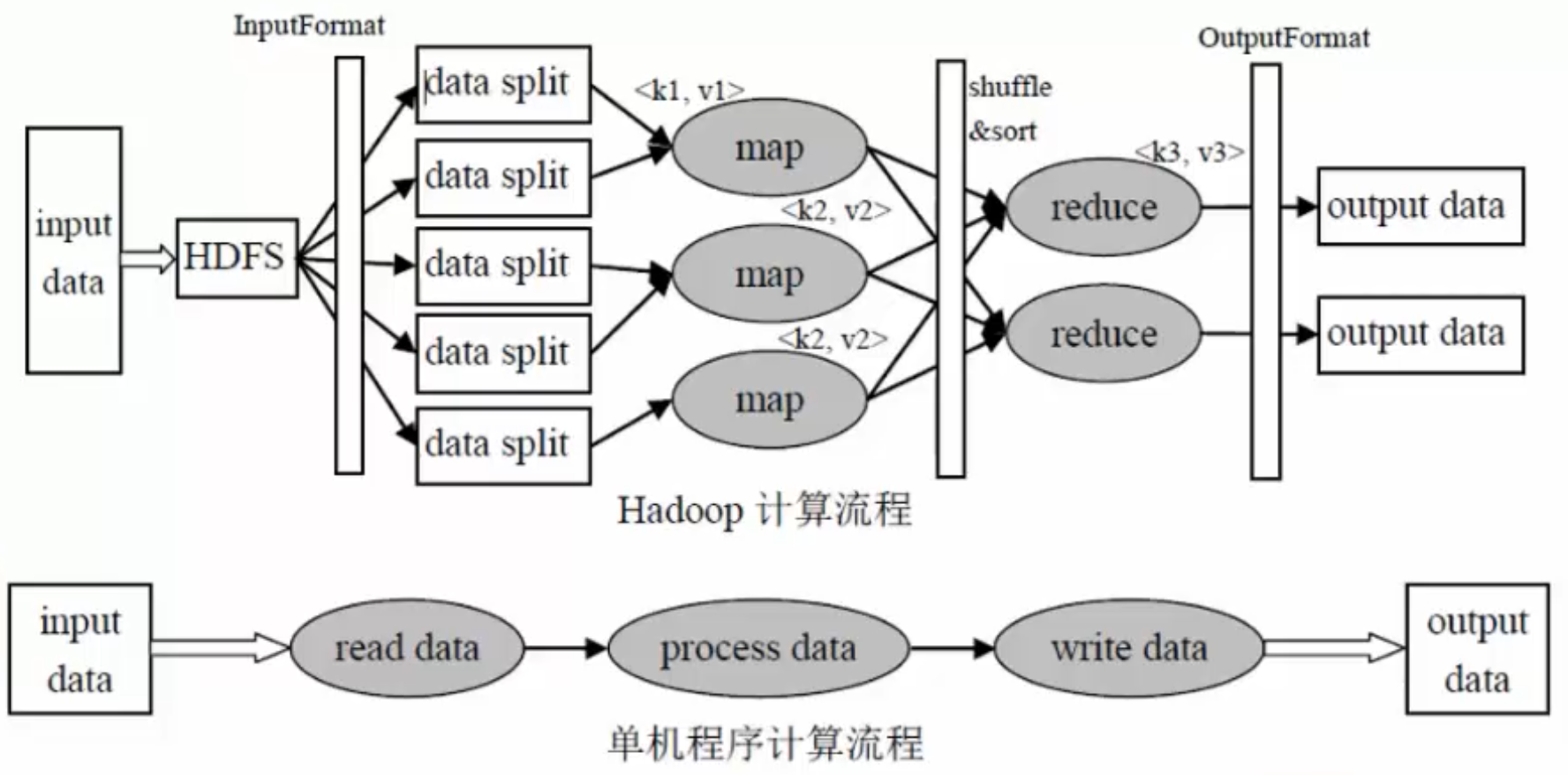
单机程序计算流程
输入数据--->读取数据--->处理数据--->写入数据--->输出数据
Hadoop计算流程
input data:输入数据
InputFormat:对数据进行切分,格式化处理
map:将前面切分的数据做map处理(将数据进行分类,输出(k,v)键值对数据)
shuffle&sort:将相同的数据放在一起,并对数据进行排序处理
reduce:将map输出的数据进行hash计算,对每个map数据进行统计计算
OutputFormat:格式化输出数据
总体处理流程图:
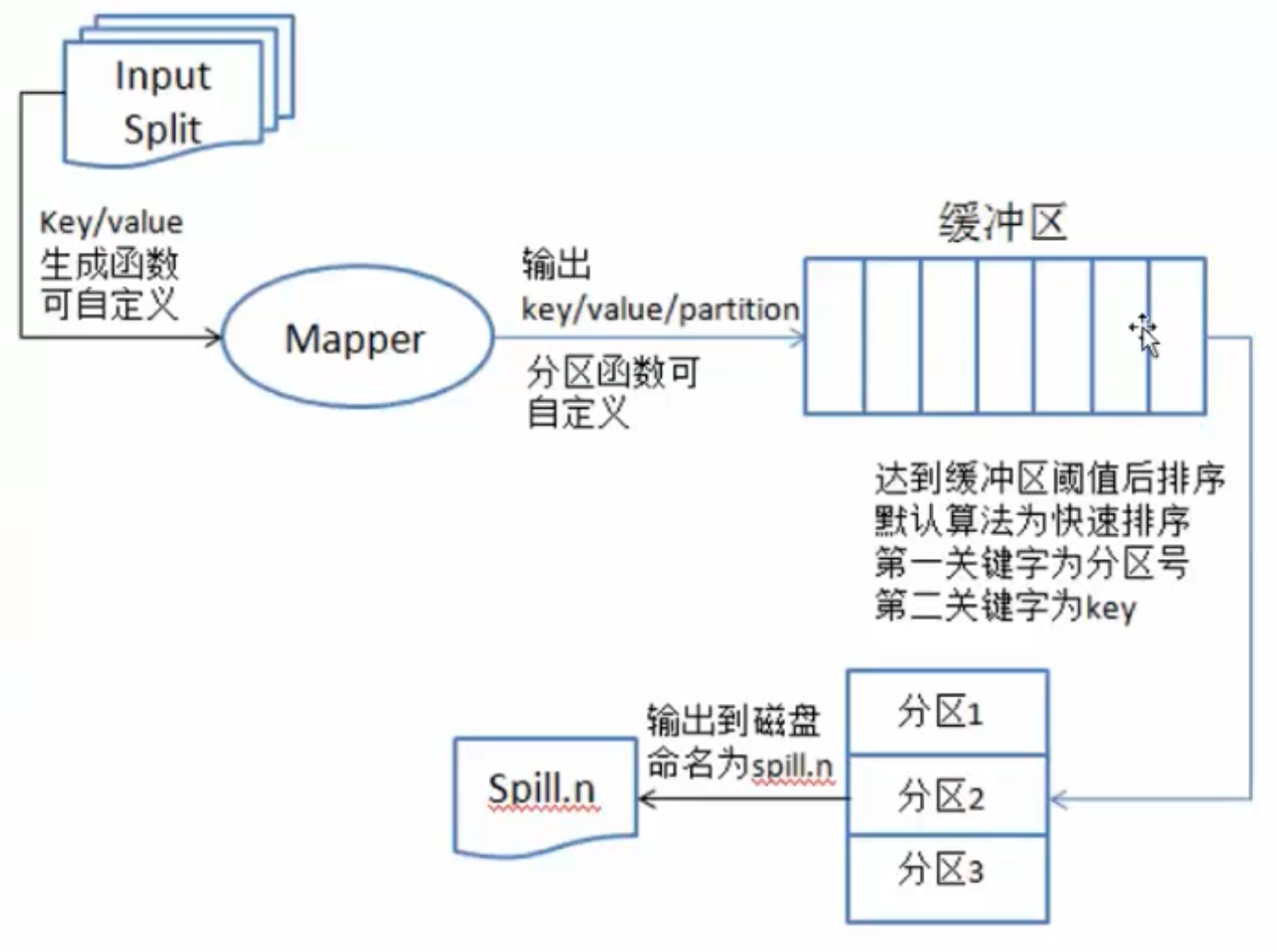
通过Mapper之后数据存在缓冲区后,对数据进行排序,最终输出到磁盘上命名为spill.n
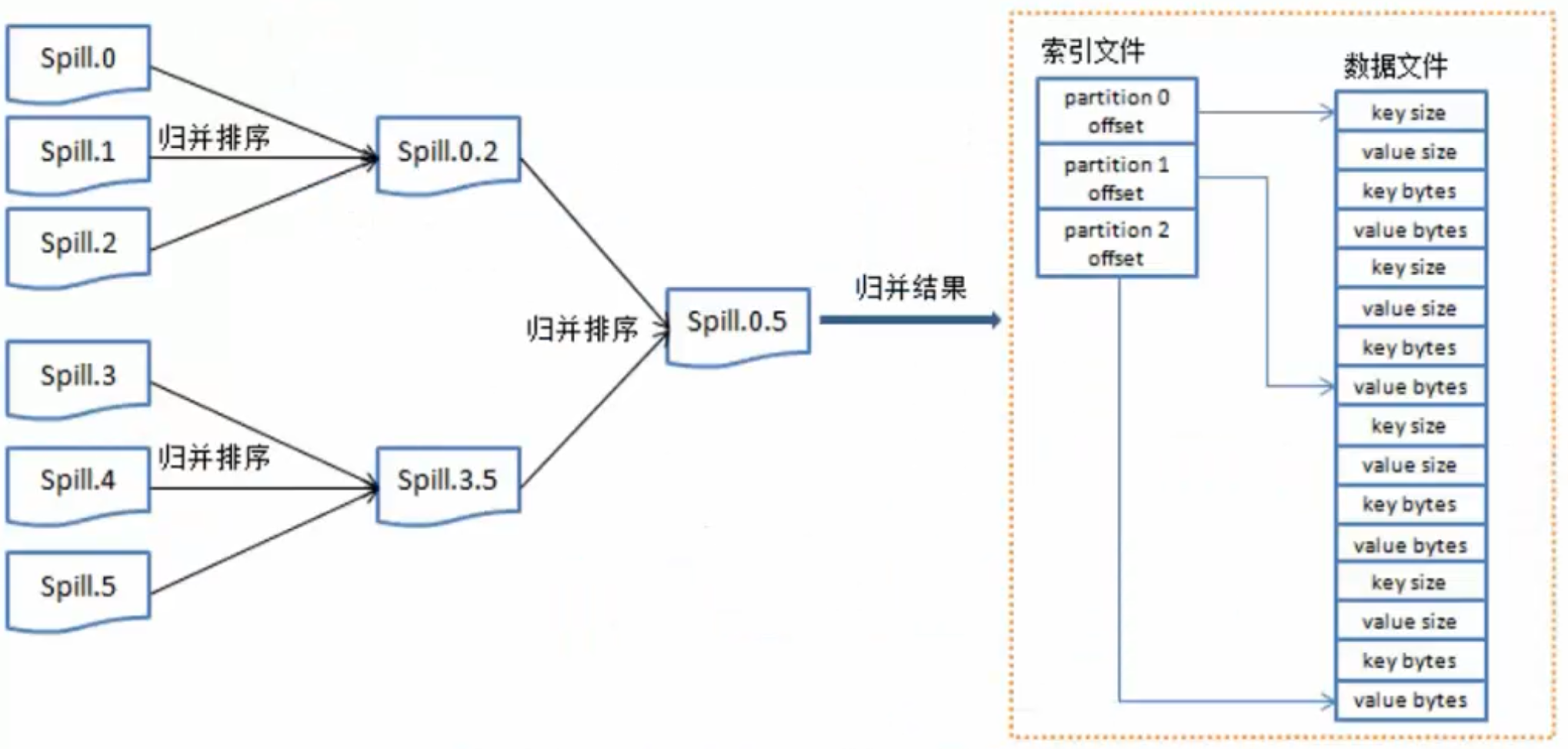
将每个splill进行归并排序,最终得到排序结果
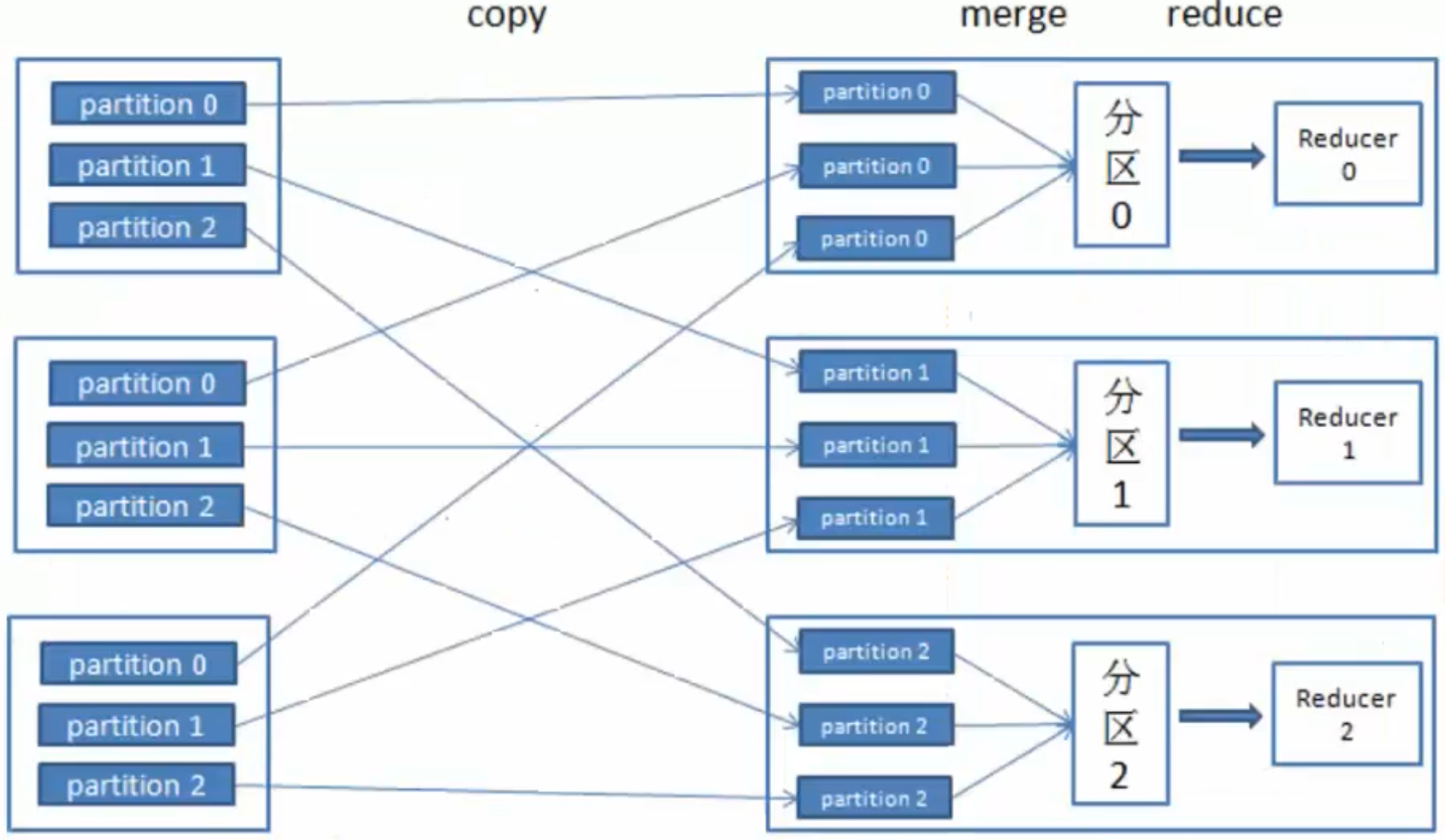
将相同数据发送到不同的分区上

map:将数据进行处理
buffer in memory:达到80%数据时,将数据锁在内存上,将这部分输出到磁盘上
partitions:在磁盘上有很多"小的数据",将这些数据进行归并排序。
merge on disk:将所有的"小的数据"进行合并。
reduce:不同的reduce任务,会从map中对应的任务中copy数据
在reduce中同样要进行merge操作
编程模型
借鉴函数式编程方式
用户只需要实现两个函数接口:
Map(in_key,in_value)
--->(out_key,intermediate_value) list
Reduce(out_key,intermediate_value) list
--->out_value list
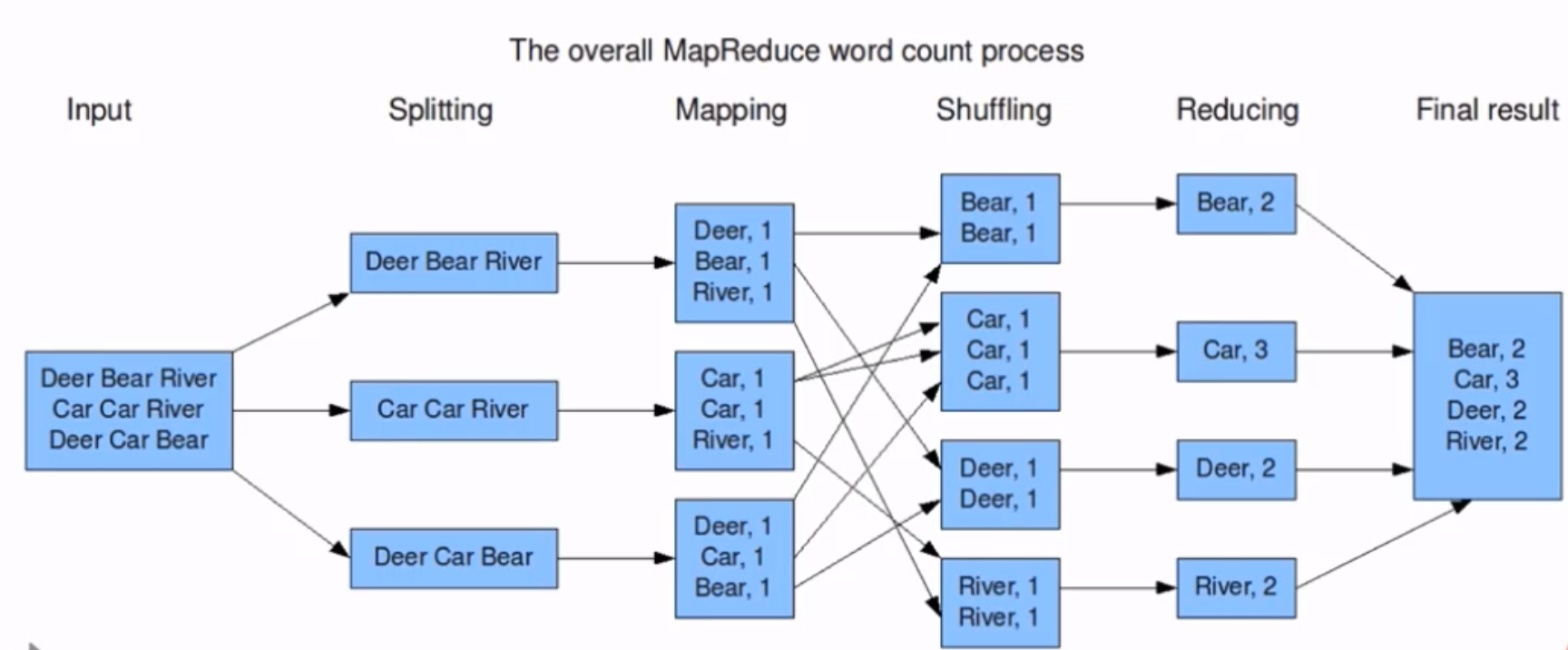
Word Count 词频统计案例
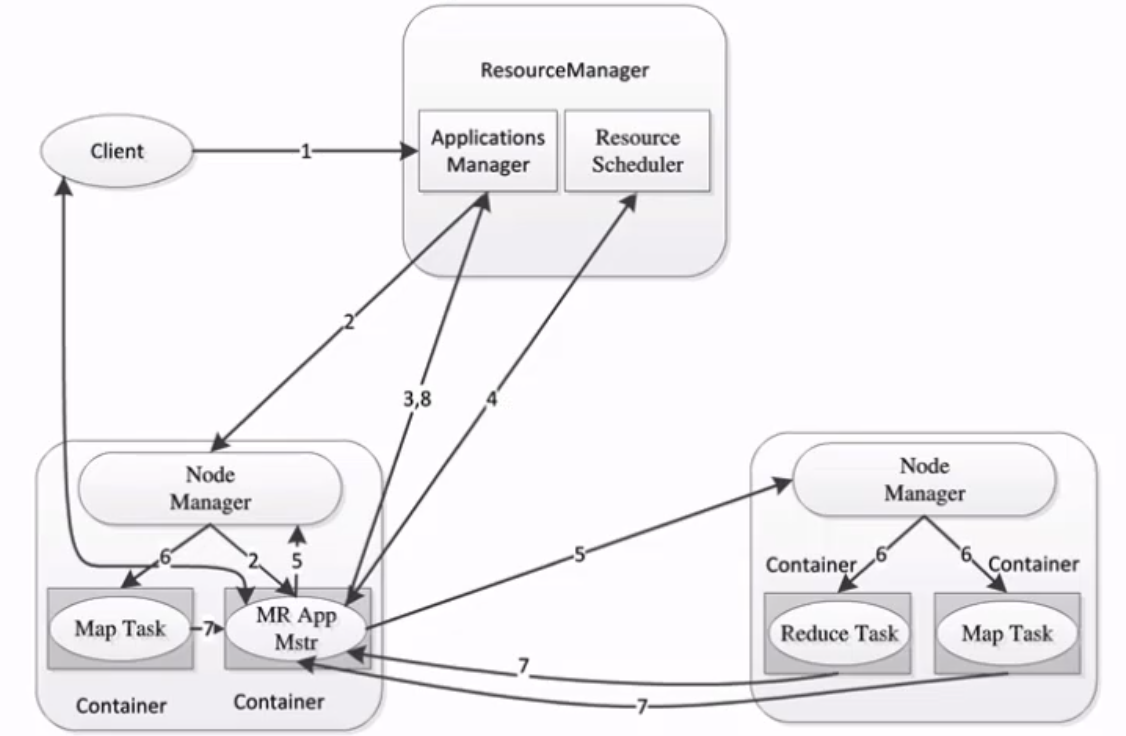
3.2.3 MapReduce架构
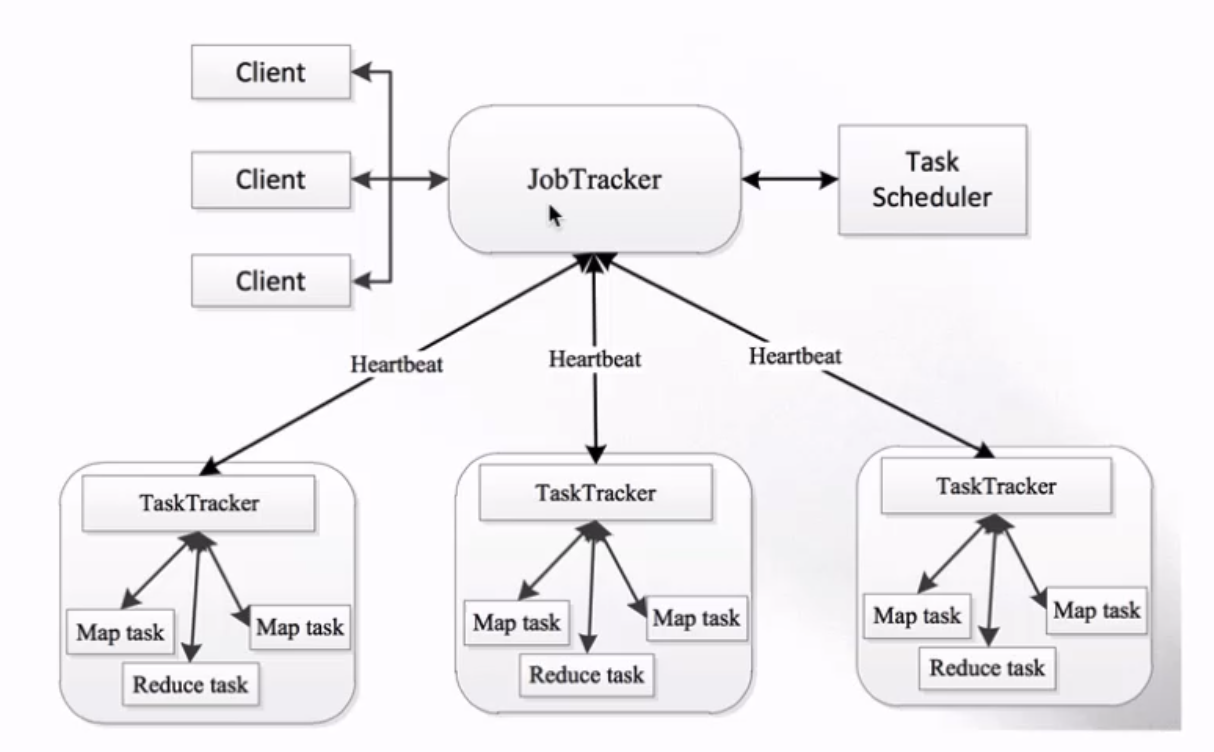
MapReduce架构 1.X
- JobTracker:负责接收客户作业提交,负责任务到作业节点上运行,检查作业的状态
- TaskTracker:由JobTracker指派任务,定期向JobTracker汇报状态,在每一个工作节点上永远只会有一个TaskTracker
MapReduce2.X架构
- ResourceManager:负责资源的管理,负责提交任务到NodeManager所在的节点运行,检查节点的状态
- NodeManager:由ResourceManager指派任务,定期向ResourceManager汇报状态