1.1 实时流处理
实时流处理概述
- 实时计算:数据的即时处理
- 流式计算:数据是持续不断的输入的
- 实时流式计算:将上述两个概念结合
初识实时流处理
需求:统计网站每个指定模块访问的客户端、 地域信息分布
实现步骤:
1,将客户端访问的内容中有效部分取出(模块编号,ip信息,useragent)
地域:通过ip转换
客户端:useragent获取
2,进行相应的统计分析操作:MapReduce/Spark
项目架构:
日志收集:Flume
离线分析:MapReduce/Spark
统计结果图形化展示
问题:
如果时间间隔逐渐减小(1h,10m,1m,若干s)
实时流处理产生背景
- 时效性高
- 数据量大
- 业务变化快
离线计算和实时计算的的对比
(1)数据来源
离线:HDFS,历史数据,数据量比较大
实时:消息队列(kafka),实时新增/修改记录过来的某一笔数据
(2)处理过程
离线:MapReduce map+reduce
实时:Spark(DStream/SS)
(3)处理速度
离线:慢
实时:快
(4)进程
离线:启动+销毁
实时:7*24
实时流处理框架对比
Storm
Apache Storm is a free and open source distributed realtime computation system.
Storm是一个免费和开源的分布式实时计算系统
Spark Streaming
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams
Spark Streaming是一个Spark核心api的扩展,支持扩展,高吞吐,容错的实时流处理框架
Flink
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink被设计成在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算
实时流处理架构
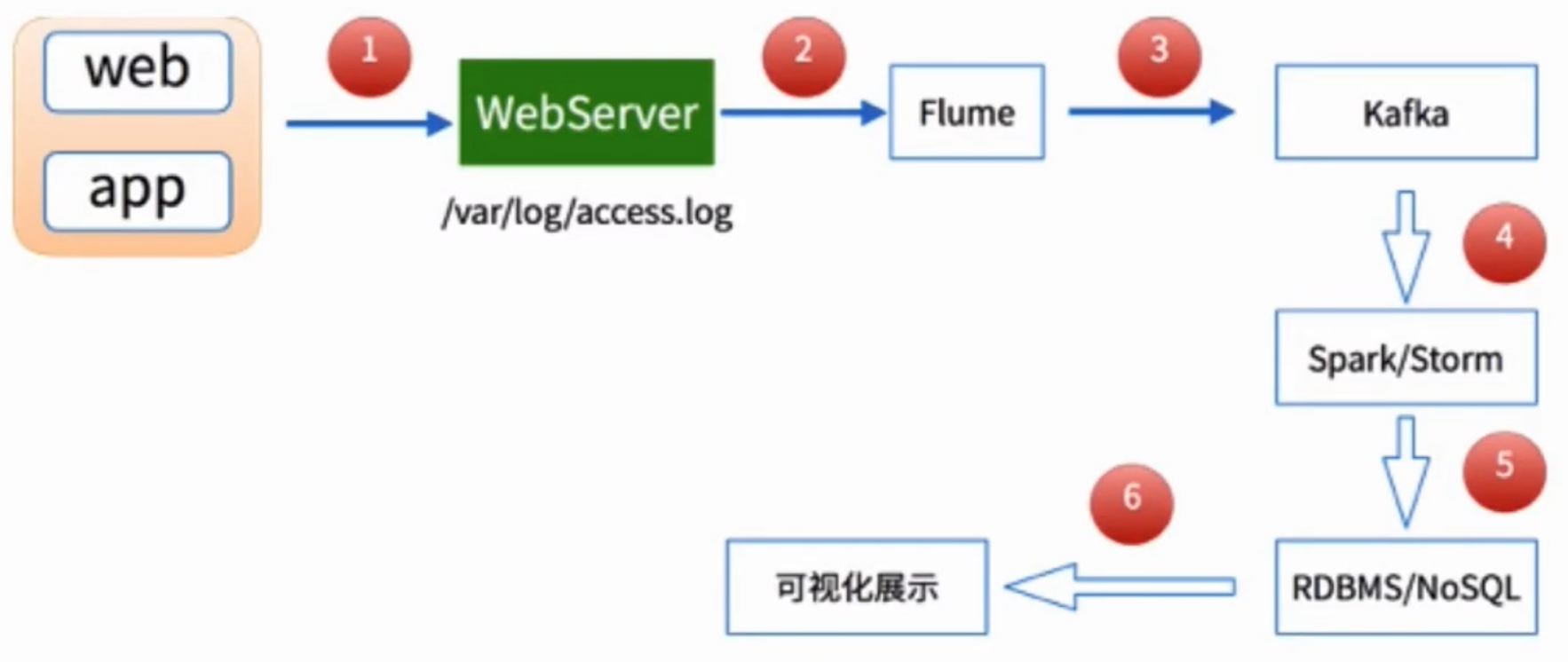
实时流处理在企业中的应用
- 电信行业:流量快用尽时,发送一个短信 手机软件病毒在后台发送数据,电信运营商及时发送短信发现这个病毒软件
- 电商行业:猜你喜欢