1.2 Flume概述
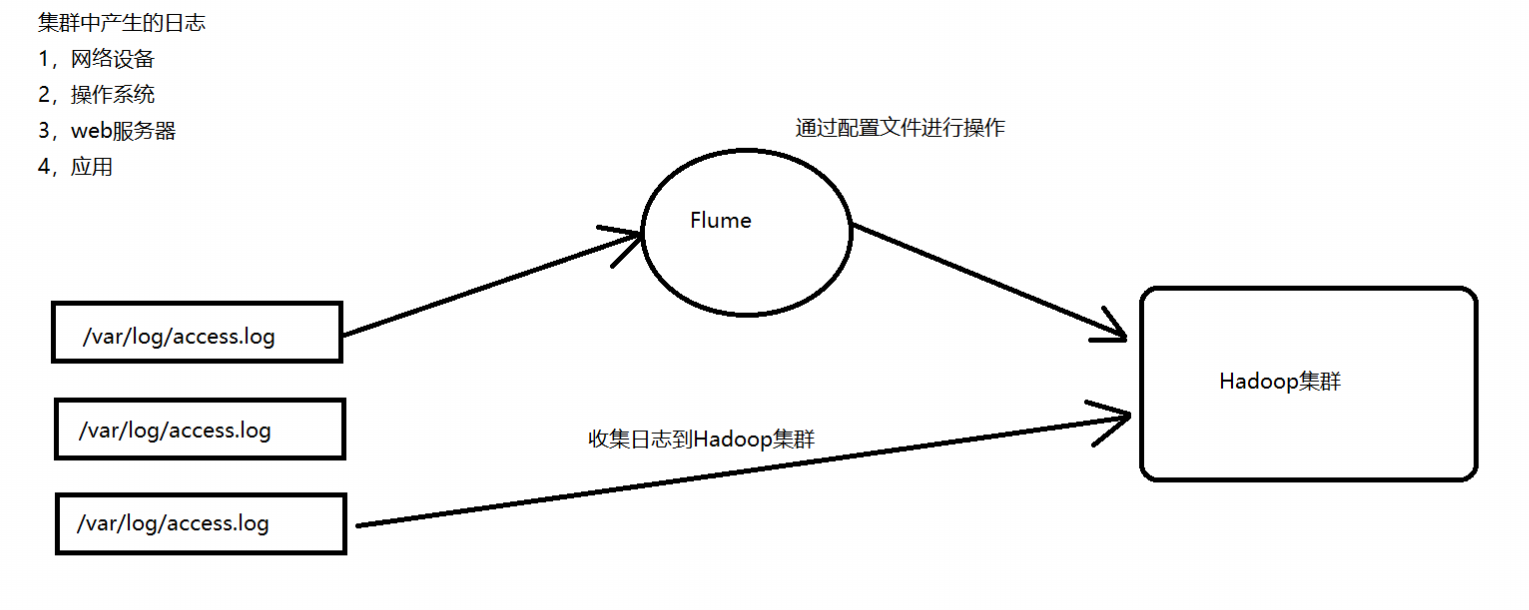
1.2.1 业务现状分析
- WebServer/ApplicationServer分散在各个机器上
- 向大数据平台Hadoop进行统计分析
- 日志如何收集到Hadoop平台上
- 日志如何收集到Hadoop平台上
- 解决方案及存在的问题
1.2.2 概述
概念
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data。
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的软件。
Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓存的数据。
Flume 支持定制各类数据发送方,用于收集各类型数据;同时,Flume 支持定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对 flume 的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume 可以适用于大部分的日常数据采集场景。
设计目标
可靠性
扩展性
- 管理性
同类产品对比
- Flume:Cloudera/Apache Java *
- Scribe:Facebook C/C++ 不再维护 对于负载均衡效果不佳
- Chukwa:Yahoo/Apache Java 不再维护 负载均衡,容错效果不佳
- Fluentd:和flume类似,Ruby
- Logstash:ELK(ElasticSearch,Logstash,Kibana) *
Flume发展史
当前 Flume 有两个版本。Flume 0.9X 版本的统称 Flume OG(original generation),Flume1.X 版本的统称 Flume NG(Flume-728)(next generation)。由于 Flume NG 经过核心组件、核心配置以及代码架构重构,与 Flume OG 有很大不同,使用时请注意区分。改动的另一原因是将 Flume 纳入 apache 旗下,Cloudera Flume 改名为 Apache Flume。
2012.7 1.0
2015.5 1.6 *
~ 1.7
1.2.3 运行机制
Flume 系统中核心的角色是 agent,agent 本身是一个 Java 进程,一般运行在日志收集节点。
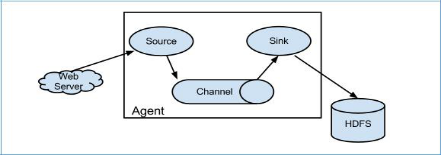
每一个 agent 相当于一个数据传递员,内部有三个组件:
Source:采集源,用于跟数据源对接,以获取数据;
Sink:下沉地,采集数据的传送目的,用于往下一级 agent 传递数据或者往
最终存储系统传递数据;
Channel:agent 内部的数据传输通道,用于从 source 将数据传递到 sink;在整个数据的传输的过程中,流动的是 event,它是 Flume 内部数据传输的最基本单元。event 将传输的数据进行封装。如果是文本文件,通常是一行记录, event 也是事务的基本单位。event 从 source,流向 channel,再到 sink,本身为一个字节数组,并可携带 headers(头信息)信息。event 代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的 event 包括:event headers、event body、event 信息,其中 event 信息就是 flume 收集到的日记记录。
flume的工作过程:先指定Source将数据进行采集,输出到Channel,Channel相当于内存存储,当Channel存储到一定值时,将数据写入到Sink中
Flume的可配置子组件
Source
Avro Source 序列化数据源
ThriftSource 序列化数据源
Exec Source 执行Linux命令行的数据源
NETCAT Source 通过指定端口,ip监控的数据源
Kafka Source 直接对接Kafka的数据源
自定义Source
Channel
- Memory Channel
- File Channel
- Kafka Channel
- JDBC Channel
Sink
HDFS Sink 写入到HDFS
Hive Sink 写入到Hive
Avro Sink 写入到序列化
HBase Sinks 写入到HBase
- HBase Sink 同步写入到HBase
- Async HBase Sink 异步写入到Hbase