1.6 Flume实战案例
日志的采集和汇总
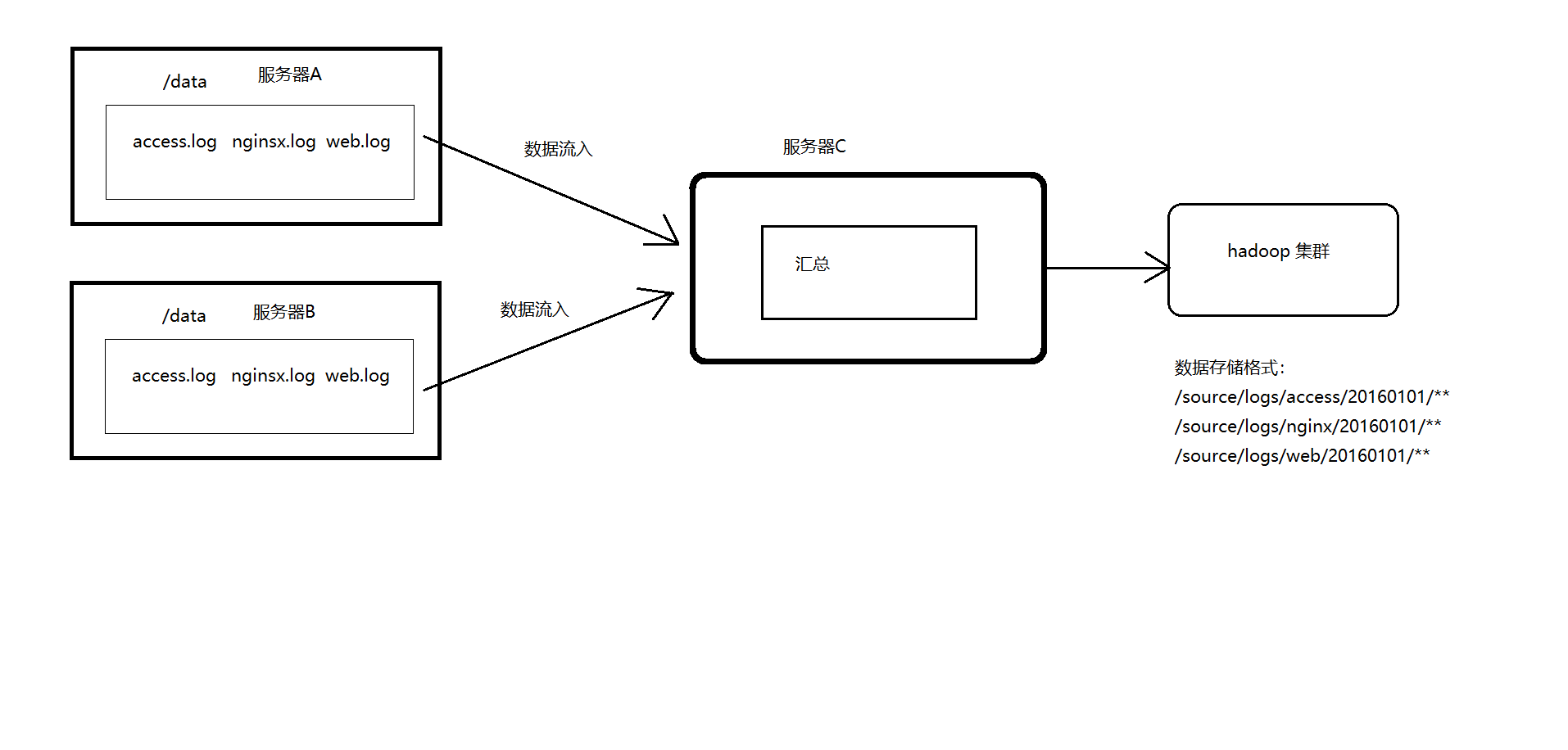
案例场景
A、B 两台日志服务机器实时生产日志主要类型为 access.log、nginx.log、web.log
现在要求:
把 A、B 机器中的 access.log、nginx.log、web.log 采集汇总到 C 机器上
然后统一收集到 hdfs 中。
但是在 hdfs 中要求的目录为:
数据放置到hdfs环境中的对应时间的目录上
/source/logs/access/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/**
关键步骤:利用拦截器在数据中添加标识,进行数据的区分
拦截器:interpreter,可以在传输的数据中添加header(key,value)形式,在数据接收方,可以通过获取key对应的value来处理数据。
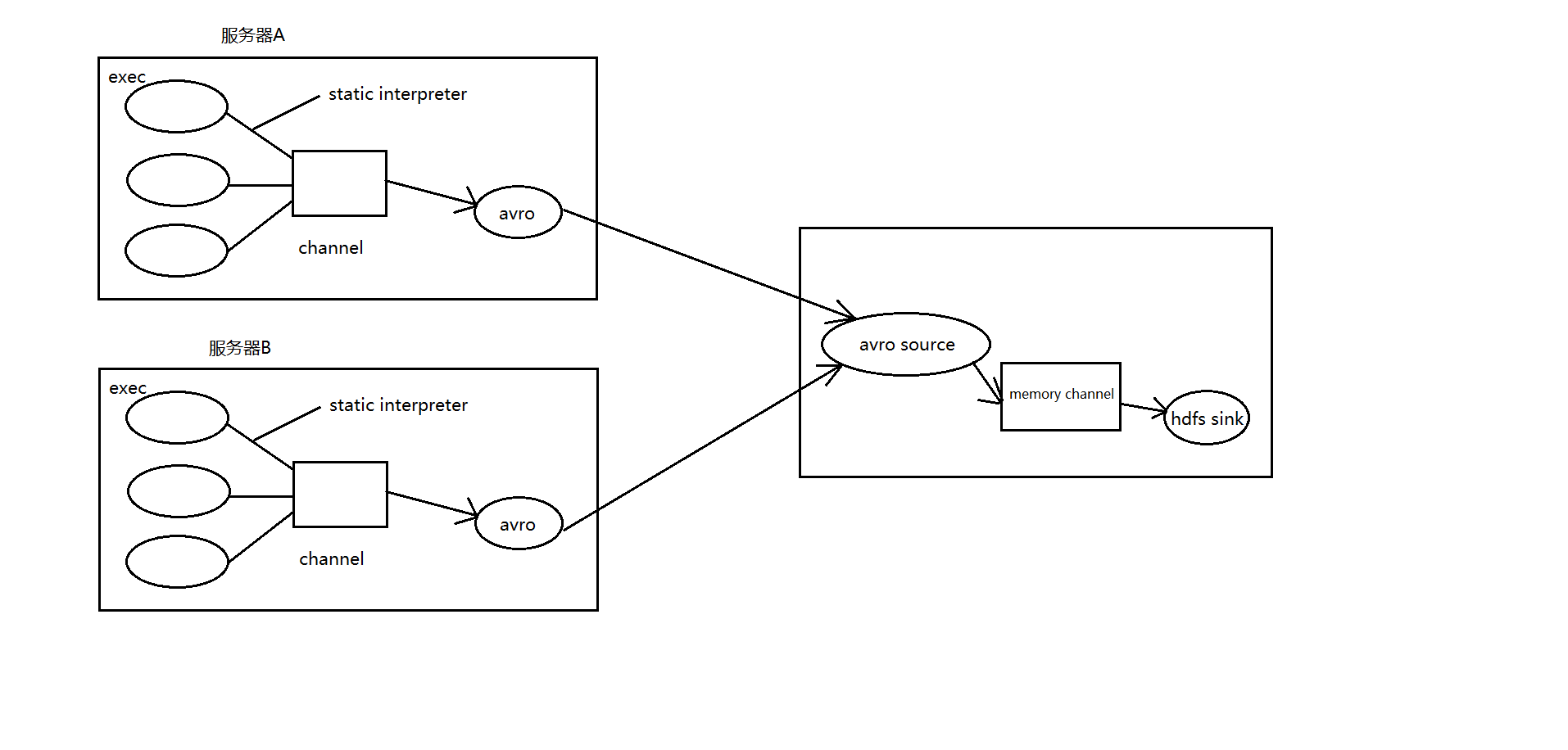
场景分析
数据流程处理分析
功能实现
① 在服务器 A 和服务器 B 上
创建配置文件 exec-memory-avro.conf
# Name the components on this agent
exec-memory-avro.sources = access-source nginx-source web-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 定义source
exec-memory-avro.sources.access-source.type = exec
exec-memory-avro.sources.access-source.command = tail -F /root/bigdata/data/access.log
#定义插入器,用于定义插入器
exec-memory-avro.sources.access-source.interceptors = i1
exec-memory-avro.sources.access-source.interceptors.i1.type = static
# static 拦截器的功能就是往采集到的数据的 header 中插入自己定义的 key-value 对
# 定义插入器的细节:type(类型),key(插入器的key),value(key对应的值)
exec-memory-avro.sources.access-source.interceptors.i1.key = type
exec-memory-avro.sources.access-source.interceptors.i1.value = access
#定义source
exec-memory-avro.sources.nginx-source.type = exec
exec-memory-avro.sources.nginx-source.command = tail -F /root/bigdata/data/nginx.log
#定义插入器,用于定义插入器
exec-memory-avro.sources.nginx-source.interceptors = i2
#定义插入器的细节:type(类型),key(插入器的key),value(key对应的值)
exec-memory-avro.sources.nginx-source.interceptors.i2.type = static
exec-memory-avro.sources.nginx-source.interceptors.i2.key = type
exec-memory-avro.sources.nginx-source.interceptors.i2.value = nginx
#定义source,思路同上,但是此时插入器的key对应的value发生的变化
exec-memory-avro.sources.web-source.type = exec
exec-memory-avro.sources.web-source.command = tail -F /root/bigdata/data/web.log
exec-memory-avro.sources.web-source.interceptors = i3
exec-memory-avro.sources.web-source.interceptors.i3.type = static
exec-memory-avro.sources.web-source.interceptors.i3.key = type
exec-memory-avro.sources.web-source.interceptors.i3.value = web
#定义sink,type为avro,绑定到node-teach1的44444端口上
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = node-teach1
exec-memory-avro.sinks.avro-sink.port = 44444
#定义channel
exec-memory-avro.channels.memory-channel.type = memory
#定义容量,为了缓存的最大数据量
exec-memory-avro.channels.memory-channel.capacity = 20000
#定义交互式容量,为了正在处理的数据量
exec-memory-avro.channels.memory-channel.transactionCapacity = 10000
#定义source/sink和channel的关联
exec-memory-avro.sources.access-source.channels = memory-channel
exec-memory-avro.sources.nginx-source.channels = memory-channel
exec-memory-avro.sources.web-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
② 在服务器 C 上创建配置文件 avro-memory-hdfs.conf 文件内容为
#定义 agent 名, source、channel、sink 的名称
avro-memory-hdfs.sources = avro-source
avro-memory-hdfs.sinks = hdfs-sink
avro-memory-hdfs.channels = memory-channel
#定义 source
avro-memory-hdfs.sources.avro-source.type = avro
avro-memory-hdfs.sources.avro-source.bind = node-teach1
avro-memory-hdfs.sources.avro-source.port =44444
#添加时间拦截器:可以将A或B机器传过来的数据进行获取,得到数据
avro-memory-hdfs.sources.avro-source.interceptors = i1
avro-memory-hdfs.sources.avro-source.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义 sink
avro-memory-hdfs.sinks.hdfs-sink.type = hdfs
#%{type} 可以将前面的数据中的key对应的value取出
avro-memory-hdfs.sinks.hdfs-sink.hdfs.path=hdfs://node-teach1:8020/source/logs/%{type}/%Y%m%d
avro-memory-hdfs.sinks.hdfs-sink.hdfs.filePrefix =events
avro-memory-hdfs.sinks.hdfs-sink.hdfs.fileType = DataStream
avro-memory-hdfs.sinks.hdfs-sink.hdfs.writeFormat = Text
#时间类型
avro-memory-hdfs.sinks.hdfs-sink.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
avro-memory-hdfs.sinks.hdfs-sink.hdfs.rollCount = 0
#生成的文件按时间生成
avro-memory-hdfs.sinks.hdfs-sink.hdfs.rollInterval = 30
#生成的文件按大小生成
avro-memory-hdfs.sinks.hdfs-sink.hdfs.rollSize = 10485760
#批量写入 hdfs 的个数
avro-memory-hdfs.sinks.hdfs-sink.hdfs.batchSize = 10000
#flume 操作 hdfs 的线程数(包括新建,写入等)
avro-memory-hdfs.sinks.hdfs-sink.hdfs.threadsPoolSize=10
#操作 hdfs 超时时间
avro-memory-hdfs.sinks.hdfs-sink.hdfs.callTimeout=30000
#定义 channels
avro-memory-hdfs.channels.memory-channel.type = memory
avro-memory-hdfs.channels.memory-channel.capacity = 20000
avro-memory-hdfs.channels.memory-channel.transactionCapacity = 10000
#组装 source、channel、sink
avro-memory-hdfs.sources.avro-source.channels = memory-channel
avro-memory-hdfs.sinks.hdfs-sink.channel = memory-channel
③ 配置完成之后,在服务器 A 和 B 上的/root/data 有数据文件 access.log、nginx.log、web.log。
模拟生成日志文件
将三种内容拼接到三个文件中
下面脚本解释:
while true:死循环
do echo "test">>/xxx/xxx.log:输出数据"test"到某个日志文件中
sleep 0.5:睡眠0.5秒
done:结束符
while true;do echo "access ..." >> /root/bigdata/data/access.log;sleep 0.5;done
while true;do echo "nginx ..." >> /root/bigdata/data/nginx.log;sleep 0.5;done
while true;do echo "web ..." >> /root/bigdata/data/web.log;sleep 0.5;done
先启动服务器 C 上的 flume,启动命令在 flume 安装目录下执行 :
flume-ng agent -f avro-memory-hdfs.conf -n avro-memory-hdfs -Dflume.root.logger=INFO,console
然后在启动服务器上的 A 和 B,启动命令在 flume 安装目录下执行 :
flume-ng agent -f exec-memory-avro.conf -n exec-memory-avro -Dflume.root.logger=INFO,console