1、初识spark-mllib
1.1 MLlib介绍
MLlib是Spark的机器学习(ML)库。其目标是使实用的机器学习可扩展且简单。从较高的层面来说,它提供了以下工具:
ML算法:常见的学习算法,如分类,回归,聚类和协同过滤 特征化:特征提取,转换,降维和选择管道。 持久性:保存和加载算法,模型和管道等。 实用程序:线性代数,统计,数据处理等。
基于Spark core的机器学习库,具有spark的优点
底层计算经过优化,比常规编码效率往往更高
实现了多种机器学习算法,可以进行模型训练及预测
Spark MLlib实现的算法
逻辑回归,朴素贝叶斯,线性回归,SVM,决策树 LDA 矩阵分解 etc
1.2 基于的api介绍
spark mllib的api基于两种
一种是基于RDD的api
一种是基于DataFrame的api
上述两种api没有什么不同
有什么影响?
- MLlib仍将支持基于RDD的API
spark.mllib以及错误修复。 - MLlib不会为基于RDD的API添加新功能。
- 在Spark 2.x版本中,MLlib将为基于DataFrames的API添加功能,以实现与基于RDD的API的功能奇偶校验。
- 在达到功能奇偶校验(粗略估计Spark 2.3)之后,将弃用基于RDD的API。
- 预计将在Spark 3.0中删除基于RDD的API。
为什么MLlib会切换到基于DataFrame的API?
- DataFrames提供比RDD更加用户友好的API。DataFrame的许多好处包括Spark数据源,SQL / DataFrame查询,Tungsten和Catalyst优化以及跨语言的统一API。
- 基于DataFrame的MLlib API跨ML算法和多种语言提供统一的API
1.3 MLlib数据格式
本地向量
本地向量是存储于本地节点上的,其基本数据是Vector。其有两个子集,分别是密集的与稀疏的,我们一般使用Vectors工厂类来生成,例如:
import pyspark.mllib.linalg as lg
#支持运算
v1 = lg.Vectors.dense(1,2,3,4)
标签数据
回忆监督学习,监督学习是(x,y)数据形式,其中这个y是标签,x是特征向量。标签数据也是一样。
from pyspark.mllib.regression import LabeledPoint
lp =LabeledPoint(1.0,Vectors.dense(1.0,2.0,3.0))
本地矩阵
与向量相似,本地矩阵类型为Matrix,分为稠密与稀疏两种类型。同样使用工厂方法Matrices来生成。但是要注意,MLlib的矩阵是按列存储的。例如下面创建一个3x3的单位矩阵:
from pyspark.mllib.linalg import Matrices
m = Matrices.dense(3,3,(1,0,0,0,1,0,0,0,1))
#显示矩阵的行列
m.numRows
m.numCols
#获取矩阵中的内容
m.values
分布式矩阵
分布式矩阵意为把一个矩阵分布式存储到多个RDD中。将分布式矩阵进行数据转换需要全局的shuffle函数,最基本的分布式矩阵是RowMatrix。
分布式数据集
RDD Dataset DataFrame都是Spark的分布式数据集的数据格式,三者在一定程度上可以相互转化,有各自的使用范围。其中RDD是最为基础与简单的一种数据集形式。
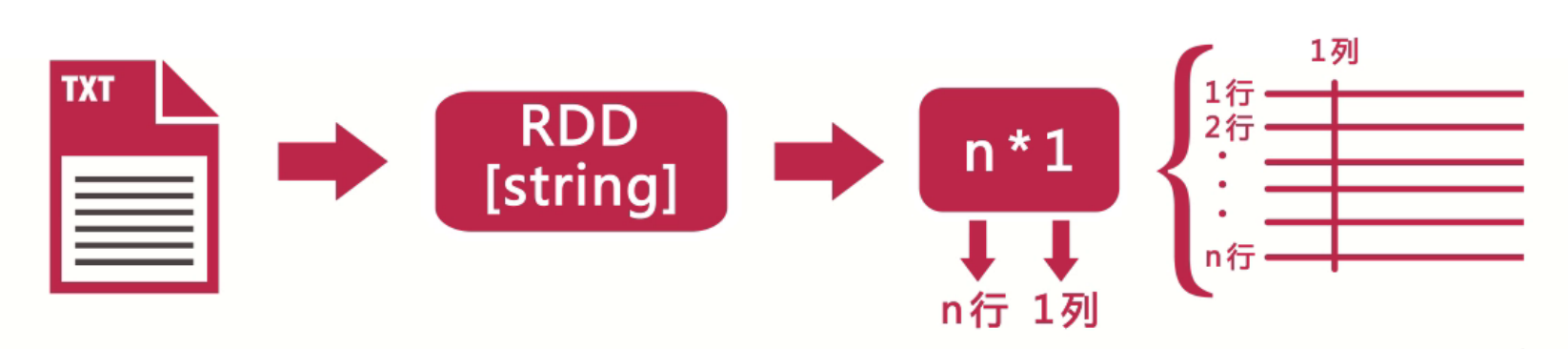
RDD
RDD(Resilient Distrubuted Datasets),弹性分布式数据集,是spark中结构最简单,也是最最常用的一类数据集形式。可以理解为把输入数据进行简单的封装之后形成的对内存数据的抽象。
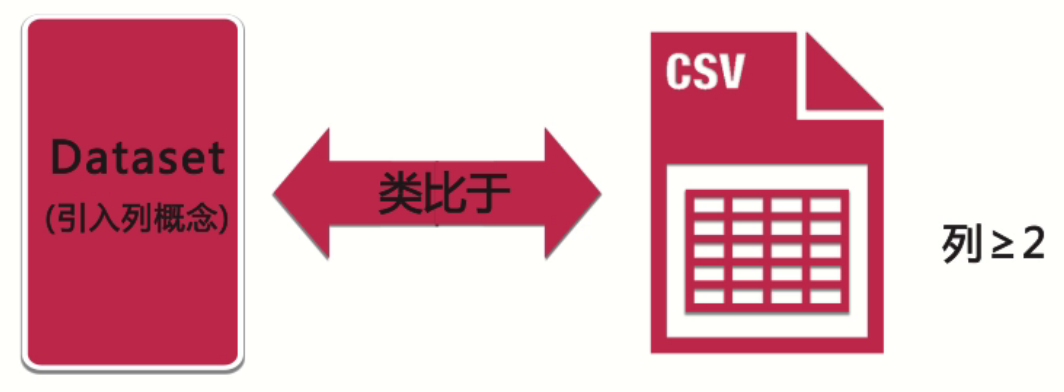
DataSet
与RDD分行存储,没有列的概念不同,Dataset引入了列的概念,这一点类似于一个csv文件结构。类似于简单的二维表。
DataFrame
DataFrame结构与Dataset是类似的,都引入了列的概念。与Dataset不同的是,DataFrame中的每一行被再次封装为Row的对象。需要通过该对象的方法来获取到具体的值。
1.4 MLlib与ml库
MLlib与ml的区别
MLlib采用RDD形式的数据结构,而ml使用DataFrame的结构
Spark官方希望用ml逐步替换MLlib
两者都会兼顾
LR_Model=LogisticRegressionWithLBFGS.train(births_train, iterations=10)
1.5 应用场景
海量数据的分析与挖掘
例如对海量的房屋出租,出售信息进行数据挖掘,预测房价价格,租金
典型数据集:波士顿房价数据集
主要用到传统的数据挖掘算法,例如使用回归算法
大数据机器学习系统
例如自然语言处理类的系统,推荐系统等
推荐系统,需要实时进行数据的收集,统计,任务调度,定期更新训练模型
核心实现:Spark Streaming +MLlib