8.5 排序模型进阶-Wide&Deep
学习目标
- 目标
- 无
- 应用
- 无
8.5.1 wide&deep
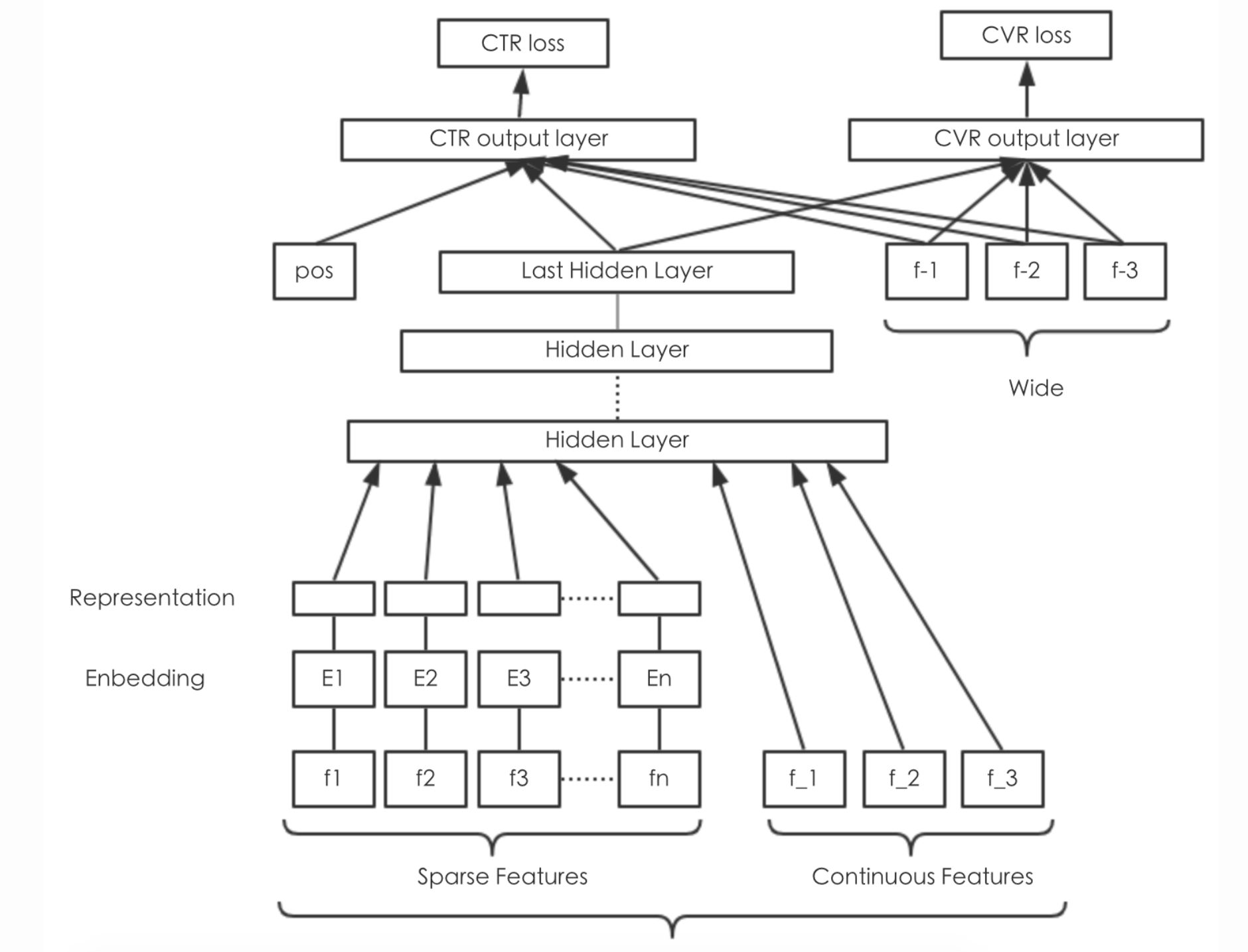
- Wide部分的输入特征:
- 离散特征
- 离散特征之间做组合
- 不输入有连续值特征的,在W&D的paper里面是这样使用的。
Deep部分的输入特征:
- raw input+embeding处理
- 对非连续值之外的特征做embedding处理,这里都是策略特征,就是乘以个embedding-matrix。在TensorFlow里面的接口是:tf.feature_column.embedding_column,默认trainable=True.
- 对连续值特征的处理是:将其按照累积分布函数P(X≤x),压缩至[0,1]内。
注:训练:notice: Wide部分用FTRL来训练;Deep部分用AdaGrad来训练。
Wide&Deep在TensorFlow里面的API接口为:tf.estimator.DNNLinearCombinedClassifier
- estimator = tf.estimator.DNNLinearCombinedClassifier()
- model_dir="",
- linear_feature_columns=wide_columns,
- dnn_feature_columns=deep_columns
- dnn_hidden_units=[]):dnn层的网络结构
- estimator = tf.estimator.DNNLinearCombinedClassifier()
tf.estimator传入参数原则
- LinearClassifier 和 LinearRegressor:接受所有类型的特征列。
- DNNClassifier 和 DNNRegressor:只接受密集列。其他类型的列必须封装在 indicator_column 或 embedding_column 中。
- DNNLinearCombinedClassifier 和 DNNLinearCombinedRegressor:
- linear_feature_columns 参数接受任何类型的特征列。
- dnn_feature_columns 参数只接受密集列。
代码:
import tensorflow as tf
class WDL(object):
"""wide&deep模型
"""
def __init__(self):
pass
@staticmethod
def read_ctr_records():
# 定义转换函数,输入时序列化的
def parse_tfrecords_function(example_proto):
features = {
"label": tf.FixedLenFeature([], tf.int64),
"feature": tf.FixedLenFeature([], tf.string)
}
parsed_features = tf.parse_single_example(example_proto, features)
feature = tf.decode_raw(parsed_features['feature'], tf.float64)
feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])
# 特征顺序 1 channel_id, 100 article_vector, 10 user_weights, 10 article_weights
# 1 channel_id类别型特征, 100维文章向量求平均值当连续特征,10维用户权重求平均值当连续特征
channel_id = tf.cast(tf.slice(feature, [0, 0], [1, 1]), tf.int32)
vector = tf.reduce_sum(tf.slice(feature, [0, 1], [1, 100]), axis=1)
user_weights = tf.reduce_sum(tf.slice(feature, [0, 101], [1, 10]), axis=1)
article_weights = tf.reduce_sum(tf.slice(feature, [0, 111], [1, 10]), axis=1)
label = tf.cast(parsed_features['label'], tf.float32)
# 构造字典 名称-tensor
FEATURE_COLUMNS = ['channel_id', 'vector', 'user_weigths', 'article_weights']
tensor_list = [channel_id, vector, user_weights, article_weights]
feature_dict = dict(zip(FEATURE_COLUMNS, tensor_list))
return feature_dict, label
dataset = tf.data.TFRecordDataset(["./train_ctr_201905.tfrecords"])
dataset = dataset.map(parse_tfrecords_function)
dataset = dataset.batch(64)
dataset = dataset.repeat()
return dataset
def build_estimator(self):
"""建立模型
:param dataset:
:return:
"""
# 离散分类
article_id = tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)
# 连续类型
vector = tf.feature_column.numeric_column('vector')
user_weigths = tf.feature_column.numeric_column('user_weigths')
article_weights = tf.feature_column.numeric_column('article_weights')
wide_columns = [article_id]
# embedding_column用来表示类别型的变量
deep_columns = [tf.feature_column.embedding_column(article_id, dimension=25),
vector, user_weigths, article_weights]
estimator = tf.estimator.DNNLinearCombinedClassifier(model_dir="./ckpt/wide_and_deep",
linear_feature_columns=wide_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[1024, 512, 256])
return estimator
if __name__ == '__main__':
wdl = WDL()
# dataset = wdl.read_ctr_records()
# lwf.train(dataset)
# lwf.train_v2(dataset)
estimator = wdl.build_estimator()
estimator.train(input_fn=wdl.read_ctr_records, steps=10000)
eval_result = estimator.evaluate(input_fn=wdl.read_ctr_records, steps=10000)
print(eval_result)